
Text Similarity¶
EarlyPrint’s Discovery Engine allows you to find a set of texts similar to any text in our corpus. It does this by using some basic measures of text similarity, and it’s easy to use if you’re interested in finding similar texts across the entire early modern corpus.
But you might be interested in finding similarity across a smaller subset of the corpus. In this tutorial, we’ll calculate similarity across the same set of 1666 texts that we used in the TF-IDF tutorial. You could easily do the same with any subset of texts that you’ve gathered using the Metadata tutorial.
This tutorial is meant as a companion to an explanation of text similarity that I wrote for The Programming Historian:
The article uses the same 1666 corpus as its example, but here we’ll work directly with the EarlyPrint XML instead of with plaintext files. For full explanations of the different similarity measures and how they’re used, please use that piece as a guide.
First, we’ll import necessary libraries. [n.b. In the Programming Historian tutorial, I use scipy’s implementation of pairwise distances. For simplicity’s sake, here we’re using Sci-kit Learn’s built-in distance function.]
import glob
import pandas as pd
from lxml import etree
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.metrics import pairwise_distances
from collections import Counter
Next we use glob to get our list of files and isolate the filekeys to use later. This is the complete list of texts we’re working with in this example. You may have a different directory or filepath for your own files.
# Use the glob library to create a list of file names
filenames = glob.glob("1666_texts_full/*.xml")
# Parse those filenames to create a list of file keys (ID numbers)
# You'll use these later on.
filekeys = [f.split('/')[-1].split('.')[0] for f in filenames]
print(filekeys)
['B02845', 'A32444', 'A51130', 'A89320', 'A36358', 'A51877', 'A46196', 'A60482', 'B04513', 'A61956', 'A46152', 'B05117', 'A32566', 'B02144', 'A35206', 'A35114', 'A32314', 'A32207', 'A29439', 'A39345', 'B03164', 'A25743', 'A86466', 'A61929', 'B03114', 'B05479', 'A53272', 'A32916', 'A70852', 'A39482', 'A41058', 'B01661', 'A61594', 'A35608', 'A76131', 'A67420', 'A64861', 'A61503', 'A66579', 'A34136', 'A77996', 'A79302', 'A62436', 'A32313', 'A38556', 'B03489', 'A32751', 'A63370', 'B05916', 'B23164', 'B09634', 'A57484', 'A92820', 'A28339', 'A52005', 'A57421', 'A39246', 'B05319', 'A52396', 'A59608', 'A64918', 'A66752', 'A26426', 'A51442', 'A26249', 'B03672', 'A56039', 'A32503', 'A55410', 'A46087', 'A54027', 'B08665', 'B03352', 'A37096', 'A31237', 'A61867', 'A61891', 'A95297', 'A50777', 'A71231', 'A28989', 'A49061', 'A27397', 'A31124', 'A63952', 'A80818', 'A65702', 'A65296', 'A30203', 'A55387', 'A59325', 'A45620', 'B06022', 'A53911', 'B03891', 'A60250', 'A93278', 'B04360', 'A96435', 'A56381', 'A61600', 'A66777', 'A39714', 'A51369', 'A48909', 'A44801', 'A71109', 'A49213', 'A63951', 'A32233', 'A43020', 'A51346', 'A45206', 'A48218', 'A95690', 'A60606', 'A23770', 'A41053', 'A52519', 'A44938', 'A64258', 'A35851', 'A56390', 'B02572', 'A91186', 'A59229', 'A46193', 'B05875', 'B05308', 'A30143', 'A47951', 'A75822', 'A46046', 'A35574', 'A29694', 'B03376', 'B03317', 'A47095', 'B01318', 'B03106', 'A44879', 'B05318', 'A54070', 'A54418', 'A32967', 'A70287', 'A75960', 'A29110', 'A50520', 'A47546', 'A37291', 'A28209', 'B02089', 'B04153', 'A59168', 'A29017', 'A47367', 'A44334', 'A81069', 'A35538', 'A46108', 'B03109', 'B02123', 'A39466', 'A96936', 'A43741', 'A55322', 'A42533', 'A42537', 'A63571', 'A87330', 'A44627', 'A92373', 'B04154', 'B20017', 'A32612', 'A93280', 'A79623', 'A38792', 'B06375', 'A47545', 'A67572', 'A46030', 'A32581', 'A44478', 'A47379', 'A41072', 'B01399', 'A26496', 'A32557', 'A37237', 'A32614', 'A39839', 'B04338', 'A48797', 'B03631', 'A45529', 'A46137', 'A58750', 'A53307', 'A41266', 'A32484', 'A50075', 'A25198', 'A42820', 'A39442', 'B02051', 'A63431', 'A77803', 'A38741', 'A49793', 'A67762', 'A45552', 'A52328', 'A97379', 'A63849', 'A23851', 'A39938', 'A44061', 'A93281', 'A67335', 'A46743', 'B04701', 'A40254', 'A40151', 'A44594', 'A80816', 'B06473', 'A39974', 'A26482', 'B05591', 'A85898', 'B06427', 'A61206', 'B06872', 'A43177', 'A32555', 'A49471', 'A47547', 'A23912', 'A36329', 'A41527', 'B04364', 'A61207', 'A41958', 'A31229', 'A96485', 'A32288', 'A59614', 'A53049', 'A36272', 'A46071', 'A42544', 'B06591', 'A32567', 'A64060', 'B05057', 'A38630', 'A63767', 'A32559', 'A33006', 'A60948', 'A53818', 'A49697', 'A57156', 'A57634', 'A65985', 'B03763', 'A41955']
Get Features¶
In order to measure similarity between texts, you need features of those texts to measure. The Discovery Engine calculates similarity across three distinct sets of features for the same texts: TF-IDF weights for word counts, LDA Topic Modeling results, and XML tag structures. As our example here, we’ll use TF-IDF.
The code below is taken directly from the TF-IDF Tutorial, where you’ll find a full explanation of what it does. We loop through each text, extract words, count them, and convert those counts to TF-IDF values.
n.b. There are two key differences between the TF-IDF tutorial and this one. Below I am getting counts of lemmas, dictionary headwords, rather than simply regularized forms of the word. This allows us to group plurals or verb forms into a single term. Also, here we’ll use L2 normalization on our TF-IDF transformation. Normalizing values helps us account for very long or very short texts that may skew our similarity results.
# Create an empty lists to put all our texts into
all_tokenized = []
# Then you can loop through the files
for f in filenames:
parser = etree.XMLParser(collect_ids=False) # Create a parse object that skips XML IDs (in this case they just slow things down)
tree = etree.parse(f, parser) # Parse each file into an XML tree
xml = tree.getroot() # Get the XML from that tree
# Now we can use lxml to find all the w tags
word_tags = xml.findall(".//{*}w")
# In this next line you'll do several things at once to create a list of words for each text
# 1. Loop through each word: for word in word_tags
# 2. Make sure the tag has a word at all: if word.text != None
# 3. Get the lemmatized form of the word: word.get('reg', word.text)
# 4. Make sure all the words are in lowercase: .lower()
words = [word.get('lemma', word.text).lower() for word in word_tags if word.text != None]
# Then we add these results to a master list
all_tokenized.append(words)
# We can count all the words in each text in one line of code
all_counted = [Counter(a) for a in all_tokenized]
# To prepare this data for Tf-Idf Transformation, we need to put into a different form, a DataFrame, using pandas.
df = pd.DataFrame(all_counted, index=filekeys).fillna(0)
# First we need to create an "instance" of the transformer, with the proper settings.
# Normalization is set to 'l2'
tfidf = TfidfTransformer(norm='l2', sublinear_tf=True)
# I am choosing to turn on sublinear term frequency scaling, which takes the log of
# term frequencies and can help to de-emphasize function words like pronouns and articles.
# You might make a different choice depending on your corpus.
# Once we've created the instance, we can "transform" our counts
results = tfidf.fit_transform(df)
# Make results readable using Pandas
readable_results = pd.DataFrame(results.toarray(), index=df.index, columns=df.columns) # Convert information back to a DataFrame
readable_results
Calculate Distance¶
Below we’ll calculate three different distance metrics—euclidean distance, “cityblock” distance, and cosine distance—and create DataFrames for each one. For explanations of each metric, and for a discussion of the difference between similarity and distance, you can refer to The Programming Historian tutorial which goes into these topics in detail.
Euclidean distance is first, because it’s the default in sklearn:
euclidean = pairwise_distances(results)
euclidean_df = pd.DataFrame(euclidean, index=df.index, columns=df.index)
euclidean_df
| B02845 | A32444 | A51130 | A89320 | A36358 | A51877 | A46196 | A60482 | B04513 | A61956 | ... | A32559 | A33006 | A60948 | A53818 | A49697 | A57156 | A57634 | A65985 | B03763 | A41955 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B02845 | 0.000000 | 1.330296 | 1.252074 | 1.343080 | 1.272442 | 1.381007 | 1.318771 | 1.320236 | 1.305981 | 1.310723 | ... | 1.330669 | 1.283922 | 1.290638 | 1.331735 | 1.315239 | 1.296993 | 1.295608 | 1.278693 | 1.288136 | 1.299440 |
| A32444 | 1.330296 | 0.000000 | 1.330771 | 1.340797 | 1.337868 | 1.370927 | 1.240466 | 1.357205 | 1.334426 | 1.345882 | ... | 1.190446 | 1.317433 | 1.315577 | 1.280773 | 1.346539 | 1.333417 | 1.315543 | 1.348345 | 1.321553 | 1.321963 |
| A51130 | 1.252074 | 1.330771 | 0.000000 | 1.316638 | 1.161953 | 1.376152 | 1.297971 | 1.226153 | 1.246694 | 1.213826 | ... | 1.324561 | 1.166884 | 1.179731 | 1.335540 | 1.186073 | 1.197500 | 1.227000 | 1.167605 | 1.233122 | 1.195988 |
| A89320 | 1.343080 | 1.340797 | 1.316638 | 0.000000 | 1.325708 | 1.237975 | 1.342863 | 1.295708 | 1.330615 | 1.311224 | ... | 1.349694 | 1.314192 | 1.304918 | 1.349898 | 1.301733 | 1.305777 | 1.314975 | 1.316260 | 1.323349 | 1.298748 |
| A36358 | 1.272442 | 1.337868 | 1.161953 | 1.325708 | 0.000000 | 1.369564 | 1.322658 | 1.258650 | 1.278494 | 1.261418 | ... | 1.328167 | 1.190528 | 1.208084 | 1.347102 | 1.199426 | 1.217275 | 1.262931 | 1.187049 | 1.225716 | 1.243505 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| A57156 | 1.296993 | 1.333417 | 1.197500 | 1.305777 | 1.217275 | 1.372673 | 1.316086 | 1.200557 | 1.246743 | 1.218061 | ... | 1.327030 | 1.110908 | 1.161417 | 1.335515 | 1.116767 | 0.000000 | 1.245640 | 1.187006 | 1.177661 | 1.204760 |
| A57634 | 1.295608 | 1.315543 | 1.227000 | 1.314975 | 1.262931 | 1.381444 | 1.327350 | 1.243357 | 1.255162 | 1.215802 | ... | 1.324041 | 1.246059 | 1.204422 | 1.330255 | 1.238637 | 1.245640 | 0.000000 | 1.252065 | 1.267028 | 1.239778 |
| A65985 | 1.278693 | 1.348345 | 1.167605 | 1.316260 | 1.187049 | 1.384899 | 1.339453 | 1.218992 | 1.254460 | 1.230040 | ... | 1.345416 | 1.129940 | 1.201704 | 1.352158 | 1.154239 | 1.187006 | 1.252065 | 0.000000 | 1.182711 | 1.213980 |
| B03763 | 1.288136 | 1.321553 | 1.233122 | 1.323349 | 1.225716 | 1.371066 | 1.327480 | 1.257738 | 1.272967 | 1.263826 | ... | 1.327534 | 1.118590 | 1.214992 | 1.324017 | 1.188736 | 1.177661 | 1.267028 | 1.182711 | 0.000000 | 1.246016 |
| A41955 | 1.299440 | 1.321963 | 1.195988 | 1.298748 | 1.243505 | 1.367297 | 1.330342 | 1.195975 | 1.219998 | 1.155711 | ... | 1.323801 | 1.196622 | 1.195257 | 1.328967 | 1.173217 | 1.204760 | 1.239778 | 1.213980 | 1.246016 | 0.000000 |
269 rows × 269 columns
Next is cityblock distance:
cityblock = pairwise_distances(results, metric='cityblock')
cityblock_df = pd.DataFrame(cityblock, index=df.index, columns=df.index)
cityblock_df
| B02845 | A32444 | A51130 | A89320 | A36358 | A51877 | A46196 | A60482 | B04513 | A61956 | ... | A32559 | A33006 | A60948 | A53818 | A49697 | A57156 | A57634 | A65985 | B03763 | A41955 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B02845 | 0.000000 | 24.650119 | 49.203414 | 38.780499 | 46.542462 | 27.171730 | 25.745305 | 78.787493 | 39.161498 | 55.773086 | ... | 25.947184 | 43.515562 | 45.353246 | 24.779750 | 75.313625 | 49.781847 | 38.587606 | 57.332514 | 36.210966 | 55.782928 |
| A32444 | 24.650119 | 0.000000 | 47.669264 | 32.272188 | 43.999466 | 19.227561 | 16.057823 | 74.819409 | 34.544138 | 51.772394 | ... | 14.635631 | 39.542522 | 40.899367 | 15.875381 | 71.247461 | 45.793170 | 33.946812 | 55.328566 | 31.591160 | 51.816649 |
| A51130 | 49.203414 | 47.669264 | 0.000000 | 56.477056 | 54.576265 | 49.983710 | 48.170012 | 84.538490 | 53.736563 | 63.487868 | ... | 48.639787 | 52.842010 | 54.400805 | 47.839720 | 77.494767 | 58.105044 | 53.010386 | 62.705428 | 52.478075 | 62.159071 |
| A89320 | 38.780499 | 32.272188 | 56.477056 | 0.000000 | 53.704863 | 30.989173 | 33.793924 | 78.858523 | 45.477574 | 58.163339 | ... | 34.014387 | 49.995994 | 50.250660 | 32.622379 | 76.028412 | 54.251285 | 44.669043 | 62.598209 | 43.635359 | 58.310558 |
| A36358 | 46.542462 | 43.999466 | 54.576265 | 53.704863 | 0.000000 | 45.860743 | 45.077440 | 85.634146 | 52.849591 | 65.225453 | ... | 44.822800 | 51.441112 | 54.023617 | 44.417045 | 76.936334 | 57.401979 | 52.306068 | 62.482273 | 48.969791 | 63.811401 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| A57156 | 49.781847 | 45.793170 | 58.105044 | 54.251285 | 57.401979 | 47.997987 | 46.659926 | 81.483471 | 51.999108 | 62.647620 | ... | 46.760935 | 47.783912 | 52.272594 | 45.851017 | 71.074501 | 0.000000 | 52.634620 | 63.482708 | 47.621520 | 61.908947 |
| A57634 | 38.587606 | 33.946812 | 53.010386 | 44.669043 | 52.306068 | 37.110046 | 35.953995 | 78.607434 | 43.045998 | 54.840913 | ... | 35.485991 | 47.947224 | 46.251104 | 34.297440 | 74.725987 | 52.634620 | 0.000000 | 61.035598 | 42.686829 | 57.116200 |
| A65985 | 57.332514 | 55.328566 | 62.705428 | 62.598209 | 62.482273 | 57.373788 | 56.423529 | 88.513195 | 60.766621 | 70.246288 | ... | 56.428125 | 56.711215 | 62.424108 | 55.515185 | 78.896892 | 63.482708 | 61.035598 | 0.000000 | 56.004211 | 68.587934 |
| B03763 | 36.210966 | 31.591160 | 52.478075 | 43.635359 | 48.969791 | 34.287528 | 33.433897 | 79.047064 | 42.843973 | 57.316811 | ... | 33.233848 | 39.478019 | 45.686447 | 31.738186 | 71.259116 | 47.621520 | 42.686829 | 56.004211 | 0.000000 | 56.758533 |
| A41955 | 55.782928 | 51.816649 | 62.159071 | 58.310558 | 63.811401 | 54.011823 | 53.286440 | 82.167830 | 55.554180 | 60.213976 | ... | 52.834872 | 58.372266 | 58.938908 | 52.005737 | 76.817342 | 61.908947 | 57.116200 | 68.587934 | 56.758533 | 0.000000 |
269 rows × 269 columns
And finally cosine distance, which is usually (but not always) preferable for text similarity:
cosine = pairwise_distances(results, metric='cosine')
cosine_df = pd.DataFrame(cosine, index=df.index, columns=df.index)
cosine_df
| B02845 | A32444 | A51130 | A89320 | A36358 | A51877 | A46196 | A60482 | B04513 | A61956 | ... | A32559 | A33006 | A60948 | A53818 | A49697 | A57156 | A57634 | A65985 | B03763 | A41955 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B02845 | 0.000000 | 0.884843 | 0.783845 | 0.901932 | 0.809554 | 0.953590 | 0.869578 | 0.871511 | 0.852793 | 0.858997 | ... | 0.885339 | 0.824228 | 0.832873 | 0.886759 | 0.864926 | 0.841096 | 0.839300 | 0.817528 | 0.829647 | 0.844272 |
| A32444 | 0.884843 | 0.000000 | 0.885475 | 0.898868 | 0.894945 | 0.939720 | 0.769378 | 0.921002 | 0.890346 | 0.905700 | ... | 0.708580 | 0.867815 | 0.865371 | 0.820190 | 0.906584 | 0.889000 | 0.865327 | 0.909017 | 0.873252 | 0.873793 |
| A51130 | 0.783845 | 0.885475 | 0.000000 | 0.866768 | 0.675067 | 0.946897 | 0.842365 | 0.751725 | 0.777123 | 0.736687 | ... | 0.877231 | 0.680809 | 0.695882 | 0.891833 | 0.703385 | 0.717004 | 0.752764 | 0.681651 | 0.760295 | 0.715194 |
| A89320 | 0.901932 | 0.898868 | 0.866768 | 0.000000 | 0.878750 | 0.766291 | 0.901640 | 0.839429 | 0.885268 | 0.859654 | ... | 0.910837 | 0.863551 | 0.851406 | 0.911112 | 0.847254 | 0.852526 | 0.864579 | 0.866271 | 0.875627 | 0.843373 |
| A36358 | 0.809554 | 0.894945 | 0.675067 | 0.878750 | 0.000000 | 0.937853 | 0.874712 | 0.792100 | 0.817274 | 0.795588 | ... | 0.882013 | 0.708679 | 0.729733 | 0.907342 | 0.719311 | 0.740879 | 0.797497 | 0.704543 | 0.751190 | 0.773152 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| A57156 | 0.841096 | 0.889000 | 0.717004 | 0.852526 | 0.740879 | 0.942116 | 0.866042 | 0.720669 | 0.777184 | 0.741836 | ... | 0.880504 | 0.617059 | 0.674445 | 0.891801 | 0.623584 | 0.000000 | 0.775809 | 0.704492 | 0.693443 | 0.725723 |
| A57634 | 0.839300 | 0.865327 | 0.752764 | 0.864579 | 0.797497 | 0.954194 | 0.880929 | 0.772968 | 0.787716 | 0.739087 | ... | 0.876542 | 0.776331 | 0.725316 | 0.884790 | 0.767111 | 0.775809 | 0.000000 | 0.783833 | 0.802680 | 0.768525 |
| A65985 | 0.817528 | 0.909017 | 0.681651 | 0.866271 | 0.704543 | 0.958973 | 0.897067 | 0.742971 | 0.786835 | 0.756500 | ... | 0.905072 | 0.638383 | 0.722046 | 0.914166 | 0.666133 | 0.704492 | 0.783833 | 0.000000 | 0.699403 | 0.736874 |
| B03763 | 0.829647 | 0.873252 | 0.760295 | 0.875627 | 0.751190 | 0.939911 | 0.881102 | 0.790952 | 0.810223 | 0.798628 | ... | 0.881173 | 0.625622 | 0.738102 | 0.876510 | 0.706546 | 0.693443 | 0.802680 | 0.699403 | 0.000000 | 0.776278 |
| A41955 | 0.844272 | 0.873793 | 0.715194 | 0.843373 | 0.773152 | 0.934750 | 0.884905 | 0.715178 | 0.744197 | 0.667834 | ... | 0.876224 | 0.715953 | 0.714320 | 0.883077 | 0.688219 | 0.725723 | 0.768525 | 0.736874 | 0.776278 | 0.000000 |
269 rows × 269 columns
Reading Results¶
Now that we have DataFrames of all our distance results, we can easily look at the texts that are most similar (i.e. closest in distance) to a text of our choice. We’ll use the same example as in the TF-IDF tutorial: Margaret Cavendish’s The Blazing World.
top5_cosine = cosine_df.nsmallest(6, 'A53049')['A53049'][1:]
print(top5_cosine)
A29017 0.558313
A61207 0.575897
A59608 0.599391
A56381 0.611200
A66752 0.611516
Name: A53049, dtype: float64
We now have a list of text IDs and their cosine similarities, but this list is hard to interpret without more information. We can use the techniques from the Metadata tutorial to get a DataFrame of metadata for all the 1666 texts:
# Get the full list of metadata files
# (You'll change this line based on where the files are on your computer)
metadata_files = glob.glob("../../epmetadata/header/*.xml")
nsmap={'tei': 'http://www.tei-c.org/ns/1.0'}
all_metadata = [] # Empty list for data
index = [] # Empty list for TCP IDs
for f in metadata_files: # Loop through each file
tcp_id = f.split("/")[-1].split("_")[0] # Get TCP ID from filename
if tcp_id in filekeys:
metadata = etree.parse(f, parser) # Create lxml tree for metadata
title = metadata.find(".//tei:sourceDesc//tei:title", namespaces=nsmap).text # Get title
# Get author (if there is one)
try:
author = metadata.find(".//tei:sourceDesc//tei:author", namespaces=nsmap).text
except AttributeError:
author = None
# Get date (if there is one that isn't a range)
try:
date = metadata.find(".//tei:sourceDesc//tei:date", namespaces=nsmap).get("when")
except AttributeError:
date = None
# Add dictionary of data to data list
all_metadata.append({'title':title,'author':author,'date':date})
# Add TCP ID to index list
index.append(tcp_id)
# Create DataFrame with data and indices
metadata_df = pd.DataFrame(all_metadata, index=index)
metadata_df
| title | author | date | |
|---|---|---|---|
| A48797 | Wonders no miracles, or, Mr. Valentine Greatra... | Lloyd, David, 1635-1692. | 1666 |
| A44938 | A fast-sermon, preached to the Lords in the Hi... | Hall, George, 1612?-1668. | 1666 |
| B02089 | His Majestie's most gracious speech to both Ho... | England and Wales. Sovereign (1660-1685 : Char... | 1666 |
| B02144 | Seasonable thoughts of divine providence affor... | Chishull, John. | 1666 |
| A35608 | The Case of Cornelius Bee and his partners Ric... | None | 1666 |
| ... | ... | ... | ... |
| A39938 | Experimented proposals how the King may have m... | Ford, Edward, Sir, 1605-1670. | 1666 |
| A50075 | Several lavvs and orders made at the General C... | Massachusetts. | 1666 |
| B06473 | Vox civitatis: or, Londons call to her natural... | None | 1666 |
| A50777 | Exaltatio alæ The ex-ale-tation of ale / done ... | Mews, Peter, 1619-1706. | 1666 |
| A75822 | Avaritia coram tribunali: or, the miser arraig... | Gentleman that loves men more than money. | 1666 |
269 rows × 3 columns
And we can combine this with our cosine distance results to see the metadata for the texts most similar to The Blazing World:
metadata_df.loc[top5_cosine.index, ['author','title','date']]
| author | title | date | |
|---|---|---|---|
| A29017 | Boyle, Robert, 1627-1691. | The origine of formes and qualities, (accordin... | 1666 |
| A61207 | Spurstowe, William, 1605?-1666. | The spiritual chymist, or, Six decads of divin... | 1666 |
| A59608 | Shaw, Samuel, 1635-1696. | The voice of one crying in a wilderness, or, T... | 1666 |
| A56381 | Parker, Samuel, 1640-1688. | An account of the nature and extent of the div... | 1666 |
| A66752 | Wither, George, 1588-1667. | Ecchoes from the sixth trumpet. The first part... | 1666 |
You now have all the tools you need to creat your own mini Discovery Engine, one focused on exactly the texts you care most about. For more on how to interpret these results and things to watch out for when calculating similarity, refer again to The Programming Historian.
Visualizing Results¶
Now that we’ve calculated similarity among all the 1666 texts, it’s helpful to explore further by visualizing those results in different ways. The first thing we need to do is import some simple graphing libraries.
from matplotlib import pyplot as plt
import seaborn as sns
Visualizing Words¶
In our results above, we found the text most similar to Cavendish’s Blazing World: Boyle’s The Origin of Forms and Qualities. (We know this similarity makes sense because Cavendish’s Blazing World also includes a scientific treatise: Observations upon Experimental Philosophy.)
We might want to know which features—in this case individual words—“drive” the similarity between these two texts. We can do this by graphing all the words that appear in both texts according to their TF-IDF values.
Luckily, pandas lets us do so easily by selecting for the IDs of each text:
# We need to "transpose" our results so that the texts are the columns and the words are the rows.
transformed_results = readable_results.T
# Then we can graph by selecting our two texts
transformed_results.plot.scatter('A53049','A29017')
<matplotlib.axes._subplots.AxesSubplot at 0x7ff0a5aab130>
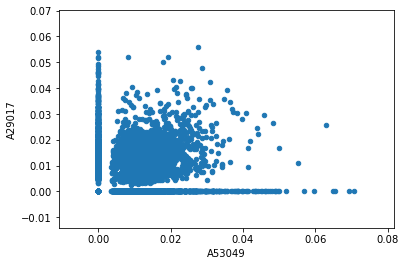
You can see there are lots of words along the x- and y-axes that only appear in one text or the other. But there are plenty of words that appear in both, with varying TF-IDF scores.
The words we’re interested in will have high TF-IDF scores in both texts—those are the words that most account for the high similarity score between these two books. We’d like to label those words on this graph.
First, we can subselect a set of words based on their TF-IDF scores in the two columns we care about. This will create a new, much smaller DataFrame:
filtered_results = transformed_results[((transformed_results['A53049'] > 0.04) & (transformed_results['A29017'] > 0.005)) | ((transformed_results['A29017'] > 0.04) & (transformed_results['A53049'] > 0.005)) | ((transformed_results['A29017'] > 0.03) & (transformed_results['A53049'] > 0.03))]
filtered_results
| B02845 | A32444 | A51130 | A89320 | A36358 | A51877 | A46196 | A60482 | B04513 | A61956 | ... | A32559 | A33006 | A60948 | A53818 | A49697 | A57156 | A57634 | A65985 | B03763 | A41955 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| chemist | 0.0 | 0.0 | 0.02112 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.008434 | 0.0 | 0.032280 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| figure | 0.0 | 0.0 | 0.00000 | 0.065961 | 0.01499 | 0.0 | 0.0 | 0.017960 | 0.0 | 0.015254 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.010337 | 0.0 | 0.000000 |
| vegetable | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.008294 | 0.0 | 0.031744 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| perception | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.022225 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.014548 |
| production | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.019591 | 0.0 | 0.012041 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.026699 | 0.000000 | 0.0 | 0.000000 |
| sensitive | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.019479 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.023907 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| immaterial | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.008745 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| mineral | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.020672 | 0.0 | 0.037429 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| experiment | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.006660 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.020265 | 0.0 | 0.007475 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.024826 |
| inanimate | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.018352 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| fluid | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.021281 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.016947 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| texture | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.009313 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| vitriol | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.014606 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| particle | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.017683 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| local | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| ice | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.020307 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.020657 |
| finite | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.015512 | 0.0 | 0.000000 | 0.025434 | 0.0 | 0.000000 |
| phaenomena | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| atom | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.015263 | 0.0 | 0.000000 |
| corpuscle | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| volatile | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.033120 | 0.000000 | 0.0 | 0.000000 |
| saline | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| camphire | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| corporeal | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| acid | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.015303 |
| incorporeal | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| perceptive | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| nitre | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| microscope | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| charcoal | 0.0 | 0.0 | 0.00000 | 0.000000 | 0.00000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
30 rows × 269 columns
These are the 30 words that drive the similarity between Cavendish and Boyle. You could adjust the threshold values in the above filter to get a bigger or smaller list of words.
And we can add these words as labels to our graph in order to see their relative TF-IDF weights:
ax = transformed_results.plot.scatter('A53049','A29017')
for txt in filtered_results.index:
x = transformed_results.A53049.loc[txt]
y = transformed_results.A29017.loc[txt]
ax.annotate(txt, (x,y))
plt.show()
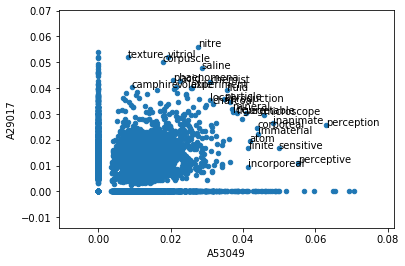
This graph tells us quite a bit about the similarity between these two texts. Words like “texture” and “corpuscle” have very high TF-IDF scores in Boyle and somewhat high scores in Cavendish. Words like “perception” and “sensitive” have very high scores in Cavendish and only somewhat high in Boyle. And a few select terms, like “microscope,” “mineral,” and “corporeal,” have high scores in both texts. This scientific vocabulary is exactly what we might expect to see driving similarity between two early science texts.
Visualizing Texts¶
In addition to visualizing the words in just two texts, it can also be helpful to visualize all of our texts at once. We can create a visualization of our entire similarity matrix by making a heatmap: a chart where values are expressed as colors.
Using the seaborn library, this is as easy as inputting our cosine distance DataFrame into a single function:
f, ax = plt.subplots(figsize=(15, 10)) # This line just makes our heatmap a little bigger
sns.heatmap(cosine_df, cmap='coolwarm_r') # This function creates the heatmap
<matplotlib.axes._subplots.AxesSubplot at 0x7ff0a593b850>
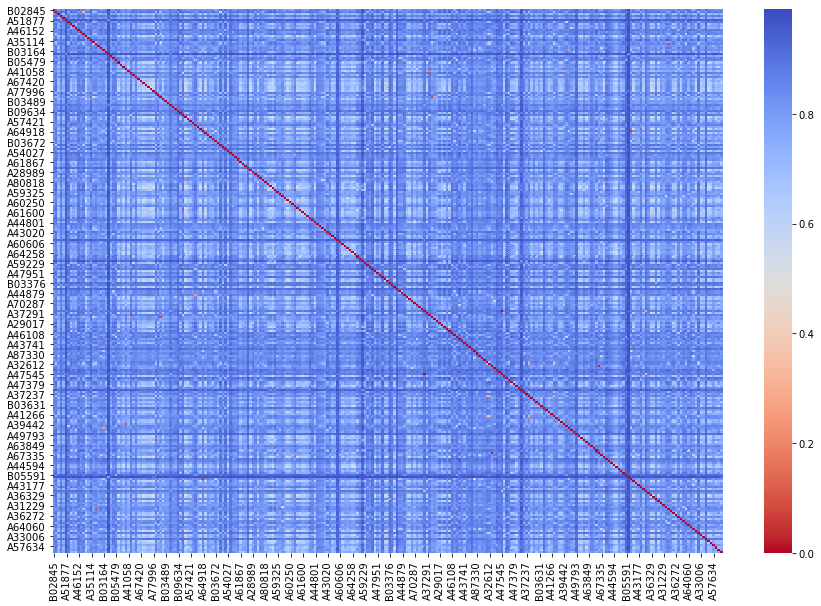
Like the word-based visualization above, this heatmap of texts is also showing us a lot that we couldn’t see just by looking at a table of numbers.
Mainly, we can see that most of the texts are not all that similar! Most of the values are showing up as blue, on the coolest end of our heatmap spectrum. [Look at the key on the right, and remember that when measuring distance higher values mean that two texts are farther apart.] This makes sense, as a group of texts published in just one year won’t necessarily use much of the same vocabulary.
Down the center diagonal of our heatmap is a solid red line. This is where a text matches with itself in our matrix, and texts are always perfectly similar to themselves.
But all is not lost: notice that some of the points are much lighter blue. These texts are more similar than the dark blue intersections, so there is some variation in our graph. And a few points that are not along the diagonal are dark red, indicating quite low distance, i.e. very high similarity. You would need to use the metadata techniques we learned above to get more information, but it’s possible that these very similar texts were written by the same author or are about the same topics.
Visualization doesn’t answer all our questions, but it allows us to view similarity measures in a few different ways. And by seeing our data anew, we can generate more research questions that require further digging: a generative cycle.